Pooling in C#
We all know pooling is useful for performance, so let's check out what .NET comes with out of the box and see how it's all used.

Pooling! It's great because we can reuse objects, skip heavy setup/initialisation/establishing/etc and go straight to using the pooled object. By doing setup once for every object in the pool rather than every time we increase performance of our application by:
- Skipping running expensive object setup
- Skipping costly finalization/IDisposable part of an object
- Reuse of memory instead of allocating new memory. This reduces the amount of memory usage and garbage collections. Less memory allocations = less garbage collection = more performant code (mostly). Especially if the objects are put into the Large Object Heap which could trigger an expensive full garbage collection
Cool, so a lot of benefit comes from only having to do setup and teardown of a reusable object once and calling the GC less. Of course there are some downsides that should be taken into consideration:
- Does what I'm writing need a pool?
- Is it worth the performance vs readability of the code? Related to the point above
- Be careful if there is data left in the pool object from a previous use (E.g. the default of
ArrayPoolin .NET Core <= 2.2) - Is the pool implementation thread safe?
- Am I properly returning the resource back to the pool?
- What are the limitations of the pooling model I'm using?
Let's dig into some of the pooling provided to us in .NET. Some is implicit - helping us under the hood and some is explicit, provided to us so we can easily implement pooling in our own code. As an aside, this post was sparked from Steve Gordon's NDC Conference presentation Turbocharged: Writing High-Performance C# and .NET Code which references the work of Konrad Kokosa and his book Pro .NET Memory Management - which I bought after watching Steve's presentation.
By the way if you see anything amiss, feel free to contact me on my about page.
Databases and Pooling
I'll only be scratching the surface of ADO.NET but it's an easy one to scratch. Pooling comes by default! It's an opt-out model that pools identical connection configurations (there's some caveats, check out the previous link).
ADO.NET
Let's play with this. I'll be using a simple ADO.NET class and Visual Studio 2019 to poke at a local database. Here's the baseline, normal ADO.NET code:
public class SimpleRepository
{
private string ConnectionString => "Data Source=(LocalDB)\\MSSQLLocalDB;AttachDbFilename=\"C:\\Users\\Niko Uusitalo\\Source\\Repos\\DatabaseConnectionPool\\DatabaseConnectionPool\\SimpleDatabase.mdf\";Integrated Security=True;";
public int InsertUsername(string username)
{
string query = @"INSERT INTO Usernames (Username) VALUES (@Username);SELECT SCOPE_IDENTITY();";
using (var connection = new SqlConnection(ConnectionString))
{
using (var command = new SqlCommand(query, connection))
{
command.Parameters.AddWithValue("@Username", username);
connection.Open();
var id = command.ExecuteScalar();
return Convert.ToInt32(id);
}
}
}
}Because pooling comes by default, we don't have to configure anything. This is a simple insert that returns the ID of the inserted row.
I call this five times:
static void Main(string[] args)
{
var repository = new SimpleRepository();
for (int i = 0; i < 5; i++)
{
repository.InsertUsername($"Niko-{i}");
}
}And I'll inspect it via queries from the Server Explorer window in Visual Studio 2019, which looks like this:
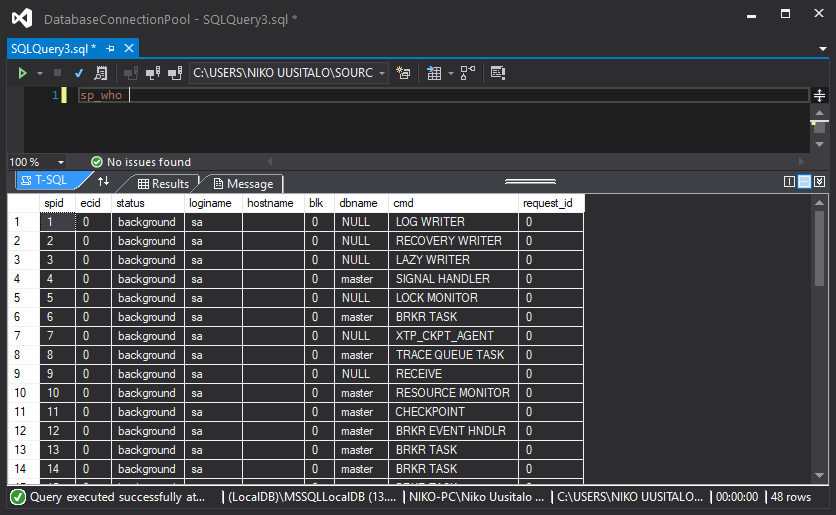
With this, let's get to experimenting. The plan is to check:
- How many connections are running by the application before executing
- Just after the
connection.Open()call - After the execution has dropped out of the
usingblock for theSqlConnectionobject - The rest of the loops
- The end when the application has closed
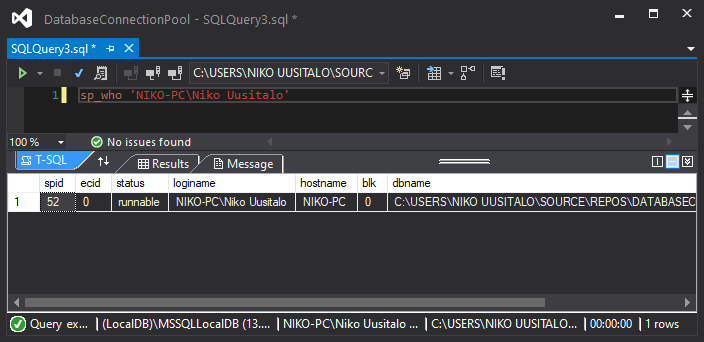
I'll be filtering down the sp_who query via sp_who 'NIKO-PC\Niko Uusitalo'
Like Mario says, "Let'sa go!"
- There is only one connection running before we start, which is the very connection I'll be using to monitor the other connections. We can safely ignore spid 52.
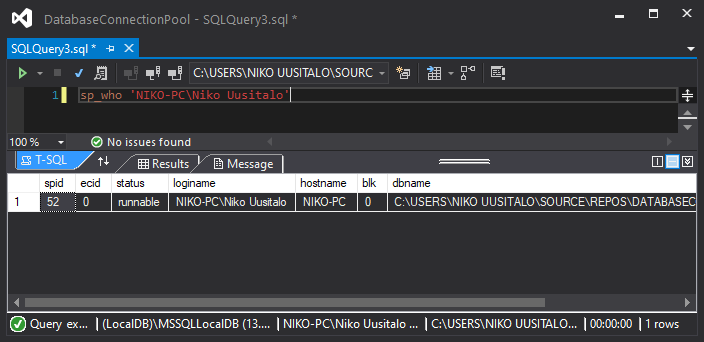
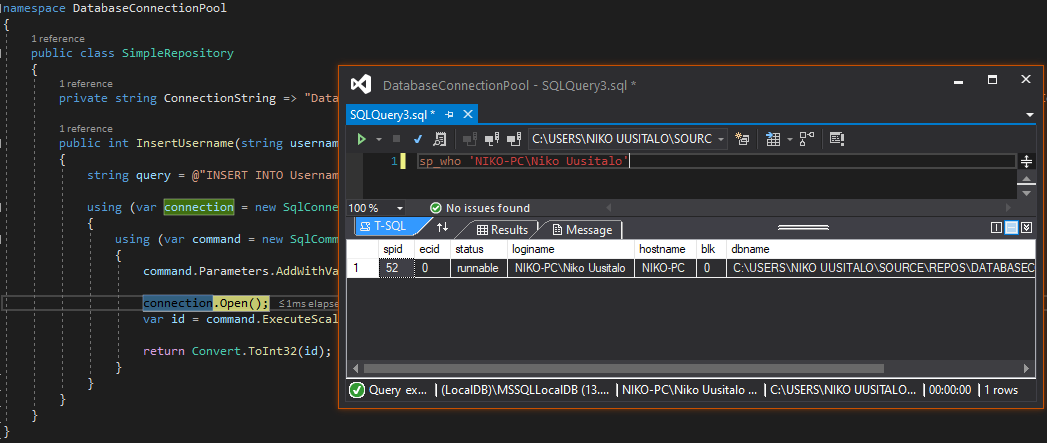
2. After hitting connection.Open() we get a new connection ID of 51 (while it is before 52, it was the next free ID, probably meaning some processes that started before 52 had already died off):
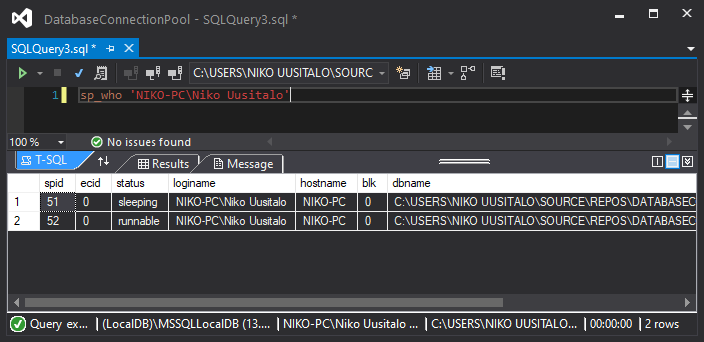
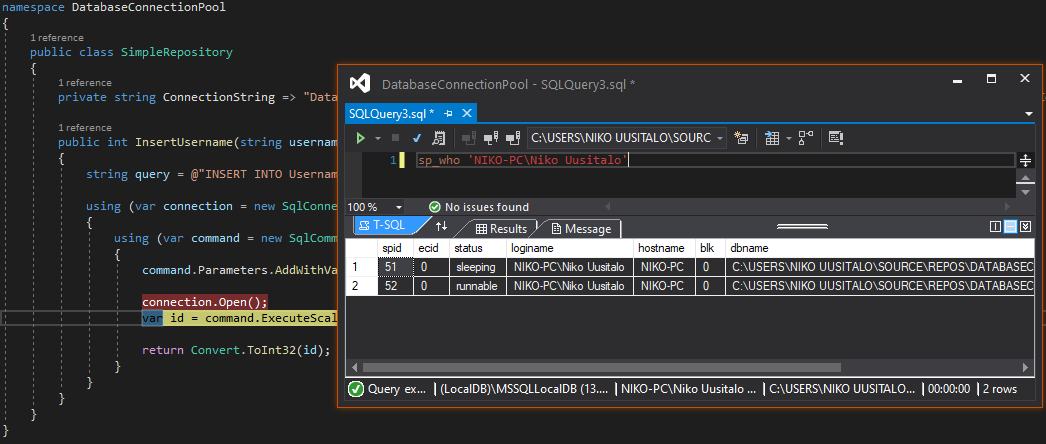
3. Dropping out of the using block we see the exact same, meaning the end of the using block didn't close the connection:
4. Without posting the same image another time, it continues to only have a single open connection, 51, as the code loops through.
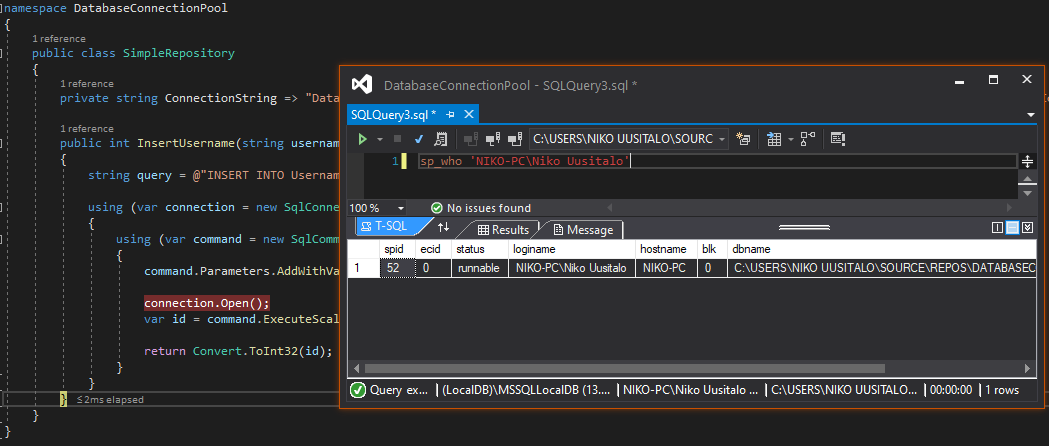
5. Finally, when the code has completed and finished debugging, we're back to only 52 - the window we're using to keep track of connections. Meaning the connection the code was using has been cleaned up:
Awesome! We validated that new connections weren't being made in the background for the same connection configuration.
We can force pooling off by adding Pooling=false to the connection string.
"Data Source=(LocalDB)\\MSSQLLocalDB;AttachDbFilename=\"C:\\Users\\Niko Uusitalo\\Source\\Repos\\DatabaseConnectionPool\\DatabaseConnectionPool\\SimpleDatabase.mdf\";Integrated Security=True;Pooling=false;"This should mean that for when we drop out of the using block for SqlConnection, our connection should go away. And it does:
That's proved it. ADO.NET pools connections meaning we get a hidden performance that we take for granted.
Entity Framework
But what about if I want to run queries with Entity Framework, do I get the bonus there too? Yes you do. EF is built on top of ADO.NET. Super easy.
Web
I'll only be focusing on one object here, HttpClient, which comes with some contention. I'll only be presenting it along with links to relevant and deep discussions.
HttpClient
Every time I used HttpClient it would be in a using block because it implements IDisposable and you should always clean up your IDisposable objects, right? But while receiving an interview question on high performance API throughput I missed the ball entirely. One of the answers they were looking for was to reuse HttpClient. It never occurred to be because I'm so conditioned to dispose asap. Turns out, immediate disposal is somewhat of an anti-pattern for HttpClient. According to the Microsoft documentation:
While this class implements IDisposable, declaring and instantiating it within a using statement is not preferred because when the HttpClient object gets disposed of, the underlying socket is not immediately released, which can lead to a socket exhaustion problem.
If you're interested in a much smarter deep dive see our friend Steve Gordan, who we met above, wrote his own post all about this. But essentially you get a pool for each unique outbound endpoint inside the HttpClient object.
This all means we want to have one HttpClient object that gets reused.
Notable Pooling Objects
What we've looked at so far are more or less implicit pooling methods where we as the developers don't need to think about it much. From here, we'll look at objects and libraries in the .NET ecosystem that aid us when we want to use pools.
ThreadPool
ThreadPool has been around since .NET Framework 1.1, making it the oldest object in this post. While still usable, it's become much easier to handle parallel tasks thanks to the abstractions in the Task Parallel Library (TPL) introduced from .NET Framework 4 onward. In fact, the TPL uses ThreadPool under the hood:
By default, TPL types like Task and Task<TResult> use thread pool threads to run tasks.
Microsoft seem to be moving toward implicit pooling as we have seen with ADO.NET, HttpClient and now the TPL.
What benefit do we get from using a ThreadPool? As we know, creating and destroying objects can be costly, meaning object reuse is favourable and threads are no different. Creating and starting a new thread is costly for a CPU due to stack allocation per thread and context switching.
This is a short entry because my personal preference is to use the TPL - but if you're working on a pre-.NET Framework 4 project or it's standard where you are to use a ThreadPool or it just floats your boat, who am I to say anything.
Recyclable Memory Stream
This is one I wish I knew about when it came out due to all the MemoryStream work I was doing at the time. You can find it here on the Microsoft Github and out of the box it's great, and to use their words:
- Eliminate Large Object Heap allocations by using pooled buffers
- Incur far fewer gen 2 GCs, and spend far less time paused due to GC
- Avoid memory fragmentation
- The semantics are close to the original
System.IO.MemoryStreamimplementation, and is intended to be a drop-in replacement
That's a lot of good stuff, it looks fantastic compared to MemoryStream and if we take another quote:
Microsoft.IO.RecyclableMemoryStream is a MemoryStream replacement that offers superior behavior
So let's check this out. I'll be using the code from a previous post on reordering PDF pages. It's a verbose and heavily IDisposable filled piece of code that uses two MemoryStream objects. The PDF I'll be using is a 40 page, 848KB file - my rice cooker manual and I'll simply be reversing the page order. To compare performance, I'll be using BenchmarkDotNet. This is the modified method:
[Benchmark]
public byte[] ReorderPagesRecycle(byte[] pdf, List<int> order)
{
using (var inputStream = manager.GetStream(pdf))
{
using (var reader = new PdfReader(inputStream))
{
using (var outputStream = manager.GetStream("Reorder", PdfSize))
{
using (var writer = new PdfWriter(outputStream))
{
using (var inputDocument = new PdfDocument(reader))
{
using (var outputDocument = new PdfDocument(writer))
{
inputDocument.CopyPagesTo(order, outputDocument);
return outputStream.GetBuffer();
}
}
}
}
}
}
}For the sake of the test there is a single private static RecyclableMemoryStreamManager manager = new RecyclableMemoryStreamManager(); call. And in the code above you're looking out for the two manager.GetStream() calls - super easy to drop in.
Now, there is also one particular caveat with Microsoft.IO.RecyclableMemoryStream meaning I won't be using it in the best light:
RecyclableMemoryStream is designed to operate primarily on chained small pool blocks. However, realistically, many people will still need to get a single, contiguous buffer for the whole stream, especially to interoperate with certain I/O APIs. For this purpose, there are two APIs which RecyclableMemoryStream overrides from its parent MemoryStream class.
Oops. With the caveat I had to move where return is called from and to use GetBuffer() instead of ToArray().
To the results:
| Method | Mean | Error | StdDev | Ratio | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|
| ReorderPagesNormal | 32.33 ms | 0.427 ms | 0.491 ms | 1.00 | 2040 | 1910 | 985 | 9.98 MB |
| ReorderPagesRecycle | 33.91 ms | 0.843 ms | 0.970 ms | 1.05 | 1700 | 1240 | 645 | 8.98 MB |
While the total performance time ~5% worse, the memory side tells a better story. With many less GC runs in all generations and a modest 1MB of memory saved. I'm sure there can be a lot of tuning, but from doing very little that's pretty neat.
If you need a more practical example, check out this post by Indy Singh.
ArrayPool
Hey if you're creating lots of arrays of T, this might be interesting to you. Found in System.Buffers is ArrayPool where we "rent" objects from the pool. A couple of things to watch out for when using it:
- You might get an array larger than what you need
- It may not be an empty array. Be cautious when blindly reading it. A change put in after .NET Core 2.2 where the arrays are cleaned on return from rental
- It's best practices to use a
try finallypattern to return the rented array:
var arrayPool = ArrayPool<int>.Shared;
var buffer = arrayPool.Rent(1024);
try
{
Process(buffer);
}
finally
{
arrayPool.Return(buffer);
}Super easy to use, just remember the things to watch out for and you're good to go!
To End
There's a few more I don't know enough on such as:
MemoryPoolObjectPool- Rolling your own with
ConcurrentBag
I enjoy the direction .NET is going with pooling; either giving us the benefits behind the scenes or creating a useful abstraction where it's easily picked up. In the last few years we've had:
- Improvements to
HttpClientin .NET Core 2.1 (May 2018) RecyclableMemoryStream(1.0.0 in Feb 2015, download spike in April 2017)MemoryPoolfrom .NET C0re 2.1 (May 2018)
I'm keen to see where .NET 5 takes us.
Reader, if you've made it this far, congrats and welcome to the end of the post. I hope you enjoyed your stay especially if it's for what you learned along the way. It's good to have you with us.